| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Autoencoder
- 베이지안
- 수달
- SQL
- 자전거 여행
- c#
- 딥러닝
- neural network
- mnist
- 소인수분해
- bayesian
- Gram matrix
- 합성곱 신경망
- 전처리
- Python
- Convolutional Neural Network
- project euler
- 오일러 프로젝트
- 오토인코더
- 소수
- deep learning
- 신경망
- 역전파
- 냥코 센세
- 역전파법
- backpropagation
- A Neural Algorithm of Artistic Style
- 히토요시
- CNN
- 비샤몬당
- Today
- Total
통계, IT, AI
딥러닝: 화풍을 모방하기 (3) - 책 요약: 3. 확률적 경사 하강법 본문
3. 확률적 경사 하강법: Stochastic Gradient Descent
3.1 경사 하강법
- 학습의 목표는 \(\boldsymbol{w}=\underset{\boldsymbol{w}}{argmin}E(\boldsymbol{w})\)을 찾는 것이다. 그런데 \(E(\boldsymbol{w})\)가 일반적으로 볼록함수가 아니기 때문에 전역 극소점을 찾는 것이 매우 어렵다. 하지만 어떤 국소 극소점에서의 \(E(\boldsymbol{w})\)가 충분히 작다면 문제를 해결할 수 있다.
- 이러한 점을 찾는 방법에는 경사 하강법이 있다.
- 먼저 다음과 같이 \(E\)의 기울기를 구한다. 단, \(M\)은 \(\boldsymbol{w}\)의 성분 수이다.
$$\nabla E(\boldsymbol{w})=\frac{\partial E}{\partial \boldsymbol{w}}=\left[ \frac{\partial E}{\partial w_1}, \cdots, \frac{\partial E}{\partial w_M} \right]^T$$
- 이후 현재의 가중치 \(\boldsymbol{w}^{(t)}\), 움직인 후의 가중치를 \(\boldsymbol{w}^{(t+1)}\)라고 한다면 다음과 같이 갱신한다.
$$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\epsilon\nabla E$$
- \(\epsilon\)은 학습률(learning rate)로 기울기를 가중치에 반영하는 정도이다.
- \(\epsilon\)이 너무 작으면 \(\boldsymbol{w}\)에 변화가 너무 적어 학습이 느리고 너무 커도 극소점에 이르지 못한다.
- 비선형함수의 최적화 방법 중에서 경사 하강법은 가장 단순한 방법으로 \(\epsilon\)을 정하는 것이 쉽지 않아 수렴이 매우 느리다. 하지만 신경망에서는 2차 미분을 구하는 것이 매우 어려워 Newton's method 등을 사용하는 것도 쉽지 않다.
3.2 확률적 경사 하강법: Stochastic Gradient Descent
- 지금까지 보인 \(E(\boldsymbol{w})\)는 각 샘플 한개에 대해서 계산되는 오차 \(E_i\)의 합으로 주어진다.
$$E(\boldsymbol{w})=\sum_{i=1}^{N}E_n(\boldsymbol{w})$$
- 마찬가지로 \(\nabla E\)도 각 샘플 한개에 대해서 계산되는 \(\nabla E_i\)의 합이다.
- 확률적 경사 하강법은 이와 다르게 샘플의 일부 또는 샘플 하나만 사용하여 파라미터를 업데이트하는 방법이다. 즉, \(\boldsymbol{w}^{(t+1)}\)을 업데이트 할 때마다 서로 다른 샘플을 사용한다.
$$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\epsilon\nabla E_i$$
- 확률적 경사 하강법은 바람직하지 않은 국소 극소점에 갇히는 위험을 줄일 수 있으며 훈련 데이터의 수집과 학습이 동시에 진행되는 등의 장점이 있어서 자주 사용된다.
3.3 미니배치(minibatch)의 이용
- 샘플 한개 단위가 아니라 몇개의 샘플을 하나로 묶어 집합 단위로 파라미터를 업데이트 할 수도 있다.
- 이 집합을 미니배치라고 부른다.
- 하나의 미니배치를 \(D_t\)라고 하자. 즉, \(t\)번째 갱신마다 샘플 집합이 변화한다는 것을 의미한다.
- \(D_t\)에 포함되는 모든 샘플에 대한 오차를 계산하여 그 기울기 방향으로 파라미터를 업데이트 한다.
$$E_t(\boldsymbol{w})=\frac{1}{N_t}\sum_{i\in D_t}E_i(\boldsymbol{w})$$
- 단, \(N_t\)는 이 미니배치가 포함하는 샘플의 개수이다.
- multi class 분류 문제에서는 비니배치마다 각 클래스의 샘플이 포함되게 하는 것이 좋다.
3.4 일반화 성능과 과적합
- 훈련데이터에 대한 오차를 훈련 오차(training error), 미지의 샘플에 대한, 정확히는 샘플 모집단에 대한 오차를 일반화 오차(generalization error)라고 부른다.
- 훈련오차와 함께 일반화 오차를 줄이는 것이 목표이지만 일반화 오차는 통계적인 기대값이므로 계산이 어렵다.
- 따라서 훈련데이터와 같은 모집단에 속해있지만 다른 데이터를 준비하여 이를 테스트 데이터라고 하고 이 테스트 데이터로 일반화 오차를 대신한다.
- 학습을 진행하면서, 훈련 오차가 감소하는 와중에 테스트 오차가 증가하게 되는 경우, 이를 과적합(overfitting) 또는 과잉적합이라고 한다. 이를 막기 위하여 테스트 오차가 증가하기 시작하면 학습을 멈출 수 있는데, 이를 조기종료(early stopping)이라 한다.
3.5 과적합을 완화시키는 방법
3.5.1 규제화: regularization
- 규제화란 파라미터의 자유도를 제약하는 방법론이다.
3.5.2 가중치 감쇠
- 가장 간단한 규제화의 방법은 파라미터에 어떤 제약을 가하는 것이다. 자주 사용되는 방법 중에는 오차함수에 가중치의 제곱합을 더하는 것이 있다.
$$E_t(\boldsymbol{w})=\frac{1}{N_t}\sum_{i\in D_t}E_i(\boldsymbol{w})+\frac{\lambda}{2}\left\| \boldsymbol{w} \right\|^2$$
-\lambda는 규제화의 강도를 제어하는 파라미터로 0.01~0.00001 정도의 범위에서 선택된다. 경사 하강법의 업데이트 식은 다음과 같다.
$$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\epsilon \left( \frac{1}{N_t} \sum_{i \in D_t} \nabla E_i + \lambda \boldsymbol{w}^{(t)} \right)$$
- 이때 가중치 감쇠는 bias에는 적용하지 않는다. 그 수가 적어 과적합이 일어나기 어려우며 때로는 큰 값을 가져야 할 때도 있기 때문이다.
- 이와 별도로 가중치의 상한을 통해 제약하는 방법이 있다. 즉, 특정 층의 \(j\)번째 유닛을 구성하는 가중치 \(w_{ji}\)에 대하여 \(\sum_{i}w_{ji}^2<c\)를 만족하게 할 수 있다.
3.5.3 드랍아웃: Drop-out
- 드랍아웃은 다층 신경망의 유닛 중 일부를 확률적으로 선택하여 학습하는 방법이다.
- 즉, 입력층과 중간층의 각 층의 유닛 중 일부를 미리 정한 비율 \(p\)만큼 선택하지 않고 학습한다.
- 미니배치를 적용하고 있다면 미니배치 단위로 유닛을 다시 선택한다.
- 학습이 끝난 뒤 추론할 때에는 모든 유닛을 사용하되 무효화된 유닛은 출력을 \(p\)배로 한다.1

- 드랍아웃은 여러개의 신경망을 훈련하여 그 결과를 평균으로 하는 것과 같은 효과가 있다. 보통 다수의 신경망의 평균을 내면 추론의 정확도가 올라가는데, 드랍아웃은 같은 효과를 적은 비용으로 하는 것이다.
- 8장에서 다룰 RBM이나 DBM 등의 학습에도 유효하며 RBM이나 자기부호화기에 이를 적용하면 희소적 특징2이 자동 학습된다는 결과가 보고된다. 즉, 5.4절에서 말하는 희소 규제화를 희소 규제화 없이 얻을 수 있다.
3.6 학습을 위한 트릭
3.6.1 데이터 정규화: normalization
- 데이터 정규화는 가장 기본적인 전처리로, 각 변수 별 평균을 0, 분산을 1로 맞춰주는 것을 말한다.
- 변동이 적은 변수의 경우 정규화를 하지 않는 경우도 있다.
3.6.2. 데이터 확장
- 이미 확보한 샘플 데이터를 일정하게 가공하여 양적으로 물타기를 할 수도 있다. 즉, \((x,d)\)에 어떤 변경을 가하여 \(({x}',d)\)를 만들 수 있다.
- 이 방법은 데이터의 분포 양상을 예상할 수 있을 때 특히 효과적이다.
- 예를 들어, 수달의 사진에 평행 이동, 반전, 회전 등을 가하거나 색에 변동을 가해도 그 사진은 수달이다.
- 가우스 분포를 따르는 랜덤 노이즈를 일괄적으로 적용하는 방법도 있다.

3.6.3 여러 신경망의 평균
- 여러개의 서로 다른 신경망을 조합하여 추정의 정확도를 향상시킬 수 있다. 물론 입력층과 출력층의 구성은 서로 같아야 하며 신경망은 서로 독립적으로 훈련시킨다.
- 복수의 신경망을 학습시켜야 하므로 비용이 많이 드는 것이 단점이다.
3.6.4. 학습률의 결정 방법
- 학습률은 학습의 성패를 좌우하는 중요한 요소로 크게 이를 결정하기 위한 두가지 방법이 있다.
- 하나는 학습 초기에는 값을 크게 설정하고 진행과 함께 학습률을 낮추는 것이다.
- 예를 들면, 파라미터 업데이트 횟수에 비례해서 작아지게 하거나 특정 횟수마다 작아지게 하는 방법이 있다.
- 또 하나는 층마다 다른 학습률을 사용하는 것이다.
- 학습률을 자동으로 결정하는 방법 중에는 AdaGrad가 가장 많이 사용된다.
- 오차함수의 기울기를 \(\nabla E_t\)라고 하고 이 벡터의 성분을 \(g_{ti}\)라고 할때 일반적인 경사하강법에서는 \(-\epsilon g_{ti}\)만큼 업데이트가 이루어지지만 AdaGrad에서는 다음과 같다.
$$-\frac{\epsilon}{\sqrt{\sum_{{t}'=1}^{t}g_{{t}'i}^2}}g_{ti}$$
- 즉, 자주 나타나는 기울기의 성분보다 드물게 나타느는 성분을 더 중시하여 파라미터를 업데이트하는 것이다.
3.6.5 모멘텀
- 경사하강법의 수렴 성능을 향상시키기 위한 방법 중의 하나로 미니배치 \(t\)에 대한 업데이트는 아래와 같다.
$$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\epsilon\nabla E_t+\mu\Delta \boldsymbol{w}^{(t-1)}$$
- 단, \(\Delta \boldsymbol{w}^{(t-1)}=\boldsymbol{w}^{(t-1)}-\boldsymbol{w}^{(t-2)}\)이며 \(\mu\)는 0.5~0.9 사이의 값으로 정한다.
- 오차함수의 골짜기 바닥이 평평한 경우, 경사하강법의 효율이 떨어지는데, 이를 해결하기 위한 방법이다.
3.6.6 가중치의 초기화
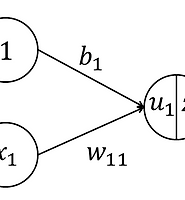
- 학습을 시작하기에 앞서 파라미터의 초기값을 정해야 한다. 단, bias는 0으로 하는 경우가 많다.
- 일반적인 방법은 정규분포로부터 임의의 값을 얻는 것이며 학습의 결과는 이 정규분포의 분산에도 영향을 받는다.
- 분산의 값이 적절하지 못하면 활성화 함수의 출력이 그 치역내에 적절한 범위에 들어오지 못하기 때문이다. 즉, \(\sum_{i}w_{ji}x_i\)가 너무 크거나 작으면 유닛의 활성화 함수의 정의역을 벗어나거나 치역의 최대값 또는 최소값을 갖기 쉽다. 그렇게 되면 미분이 0에 가깝게 되어 학습이 어렵게 된다.
- 예를 들어 \(1,000\)개의 출력층 중 절반이 1, 나머지는 0의 값을 갖는다고 하자. 파라미터의 초기값을 표준정규분포에서 취하고 bias의 초기값으로 1을 정하면 \(\sum_{i}w_{ji}x_i+1\)은 평균이 0, 분산이 501인 정규분포를 따른다. 이 범위는 매우 넓기 때문에 활성화 함수가 제대로 된 값을 갖지 못하는 원인이 된다. 이를 해결하기 위하여 파라미터의 초기값을 정할 때 분산을 노드의 수로 나누어 주는 것이 도움이 된다.
- 딥러닝에서는 사전훈련을 통하여 초기값을 정하는 방법이 일반적으로 사용된다. 또는 하이퍼 파라미터 전체를 GA(Genetic Algorithm)을 사용하여 초기화하는 방법도 있다.
3.6.7 샘플의 순서
- 일반저으로는 신경망이 익숙하지 않은 샘플을 먼저 보이는 것이 학습에 유리하다.
- 하지만 최근에는 클래스간 수에 편차만 적도록 하고 대량의 샘플과 파라미터를 어떻게 관리하는지에 더 역점을 두는 경우가 많다.
'머신러닝' 카테고리의 다른 글
| 딥러닝: 화풍을 모방하기 (5) - 연습: 이진 분류 문제 (0) | 2017.02.01 |
|---|---|
| 딥러닝: 화풍을 모방하기 (4) - 연습: 회귀 문제 (0) | 2017.01.30 |
| 딥러닝: 화풍을 모방하기 (2) - 책 요약: 2. 앞먹임 신경망 (0) | 2017.01.30 |
| 딥러닝: 화풍을 모방하기 (1) - 책 요약: 1. 시작하며 (0) | 2017.01.27 |
| 딥러닝: 화풍을 모방하기 - 시작하며 (0) | 2017.01.27 |