
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 전처리
- 딥러닝
- 비샤몬당
- 역전파법
- Convolutional Neural Network
- deep learning
- bayesian
- 수달
- 소인수분해
- 소수
- 자전거 여행
- project euler
- neural network
- 히토요시
- SQL
- 오일러 프로젝트
- 합성곱 신경망
- Autoencoder
- 역전파
- 베이지안
- 신경망
- A Neural Algorithm of Artistic Style
- mnist
- backpropagation
- Python
- Gram matrix
- 오토인코더
- 냥코 센세
- CNN
- c#
- Today
- Total
목록머신러닝 (15)
통계, IT, AI
 딥러닝: 화풍을 모방하기 (13) - 논문 구현
딥러닝: 화풍을 모방하기 (13) - 논문 구현
1. 개요 A Neural Algorithm of Artistic Style은 2015년에 발표된 논문으로, 신경망을 이용하여 특정 이미지를 다른 이미지의 화풍을 모방하여 재구성하는 내용을 담고 있다. 발표가 된 직후부터 상당히 화제가 된 논문으로 내가 신경망에 관심을 갖게 된 계기이기도 하다. 본 포스팅에서는 해당 논문에서 소개한 style transfer의 원리를 간략하게 설명하고 논문에 등장한 figure를 재현한다. 2. 원리와 재연 본 논문에서 제시하고 있는 방법은 한 이미지에서는 내용을, 다른 이미지에서는 스타일을 학습하고 결과를 적절하게 혼합하여 이미지를 생성하는 것이다. 먼저 내용을 학습하는 방법을 설명한다. Convolution layer는 filter를 통해 이미지의 특징을 잡아내는 역..
 딥러닝: 화풍을 모방하기 (12) - 연습: CNN 구현
딥러닝: 화풍을 모방하기 (12) - 연습: CNN 구현
1. 개요 CNN으로 Mnist 데이터를 학습해보자. 먼저 대략적인 구조는 그림 과 같다. 입력 데이터의 사이즈는
 딥러닝: 화풍을 모방하기 (11) - 책요약: 6. CNN
딥러닝: 화풍을 모방하기 (11) - 책요약: 6. CNN
1. 개요 CNN(Convoluional Neural Network; 합성곱 신경망)은 특히 이미지 인식 분야에서 자주 사용되는 신경망이다. 지금까지 본 신경망(이하 완전연결 신경망)과 다른 점은 그림 과 같이 합성곱층(Convolution Layer)와 풀링층(Pooling Layer)이 추가되었다는 점이다. 2. 합성곱 계층 Convolution Layer2.1. 개요 완전연결 신경망이 가진 가장 큰 문제점은 데이터의 형상이 무시된다는 것이다. 예를 들어 MNIST와 같은 이미지 데이터에서는 픽셀들이 서로 밀접한 관련을 갖고 있다. 가령 1이라는 이미지는 아래 또는 위 방향으로 비슷한 픽셀 값을 가질 확률이 높다. 게다가 컬러 이미지는 채널까지 포함하여 3차원 데이터이지만 완전연결 신경망에서는 이러한..
 [머신러닝] 나이브 베이즈 분류 Naive Bayes Classification에 대하여
[머신러닝] 나이브 베이즈 분류 Naive Bayes Classification에 대하여
1. 개요 나이브 베이즈는 베이즈 정리를 사용하는 확률 분류기의 일종으로 특성들 사이에 독립을 가정한다. 이론이 어렵지 않고 구현이 간단하며 "나이브"한 가정에도 불구하고 여러 복잡한 상황에서 잘 작동하기 때문에 다양한 분야에서 사용되고 있다. 독립변수에 따라 여러가지 모습을 가지지만 이번 포스팅에서는 어떤 메시지가 스팸(spam)인지 또는 정상(ham)인지 분류하는 문제만 고려한다. 2장에서는 나이브 베이즈 분류를 이해하기 위한 배경 지식을 간단하게 훑어보고 3장에서 나이브 베이즈가 어떤 식으로 작동하는지 살펴본다. 4장에서는 나이브 베이즈를 실제 데이터에 적용하여 텍스트 메시지를 분류해본다. 2. 배경 지식 2.1. 베이지안 통계 베이지안 통계에서는 모수
 딥러닝: 화풍을 모방하기 (10) - 연습: 자기부호화기(Autoencoder)
딥러닝: 화풍을 모방하기 (10) - 연습: 자기부호화기(Autoencoder)
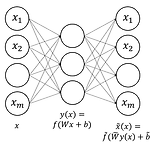
1. 개요 Autoenoder를 실습하기 위하여 두가지 주제를 진행하였다. 첫번째는 의 그림 5-6을 재연하는 것이고 두번째는 Autoencoder로 사전학습을 하여 신경망의 학습이 잘 이루어지는지 확인하는 것이다. 즉, 신경망의 층이 많아지면 학습이 잘 이루어지지 않는 현상인 Gradient vanishing을 Autoencoder로 해결할 수 있는지 알아보고자 하였다. 재연을 위한 모든 코드는 깃허브의 deeplearning 폴더에 올려두었다. 실행을 위해서는 data/mnist 폴더의 mnist_loader.py를 실행하여 pkl 파일을 생성해야 한다. 2. 그림 5-6 재연 의 그림 5-6은 자기부호화기의 파라미터가 시각적으로 어떠한 경향을 갖는지 표현한 것으로 아래 그림 1과 같다. 입력층의 노..
 딥러닝: 화풍을 모방하기 (9) - 책 요약: 5. 자기부호화기
딥러닝: 화풍을 모방하기 (9) - 책 요약: 5. 자기부호화기
5. 자기부호화기: Autoencoder5.1. 개요 자기부호화기(Autoencoder)란 출력이 입력과 같도록 설계한 신경망이다. 예를 들어 그림 5-1과 같이 입력층과 출력층의 유닛의 수가 서로 같은 2층의 신경망을 생각해보자. 1층에서는 입력
 딥러닝: 화풍을 모방하기 (8) - 연습: 역전파법
딥러닝: 화풍을 모방하기 (8) - 연습: 역전파법
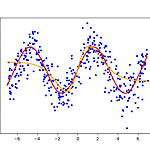
1. 회귀문제- 본 포스팅에 있는 결과는 다음 첨부파일(code.7z)을 통하여 재현이 가능하다.- 역전파법을 회귀문제에 적용해보자. 실습을 위해 정의역이
 딥러닝: 화풍을 모방하기 (7) - 책 요약: 4. 역전파법
딥러닝: 화풍을 모방하기 (7) - 책 요약: 4. 역전파법
4. 역전파법: backpropagation 4.1 기울기 계산의 어려움 - 3장에서 설명한 경사하강법을 실행하기 위해서는 식
 딥러닝: 화풍을 모방하기 (6) - 연습: 다클래스 분류 문제
딥러닝: 화풍을 모방하기 (6) - 연습: 다클래스 분류 문제
1. 개요- 입력이 4개이며 출력은 3가지 클래스를 갖는 경우를 생각해보자. 신경망은 그림 1과 같다.- 입력과 파라미터를 아래와 같이 정의한다.$$\begin{eqnarray} x_n&=&
 딥러닝: 화풍을 모방하기 (5) - 연습: 이진 분류 문제
딥러닝: 화풍을 모방하기 (5) - 연습: 이진 분류 문제
1. 개요- 변수가 2개이며 종속변수가 이진형인 경우를 생각해보자. 신경망은 그림 1과 같다.- 훈련데이터의 수는 200으로 한다. - 출력이 이진형이므로 활성함수는 sigmoid로 한다. - 즉,