| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 역전파법
- 오일러 프로젝트
- CNN
- deep learning
- 히토요시
- 베이지안
- project euler
- bayesian
- Gram matrix
- 합성곱 신경망
- c#
- neural network
- 냥코 센세
- 소인수분해
- mnist
- 소수
- 수달
- 오토인코더
- 자전거 여행
- Autoencoder
- 신경망
- 딥러닝
- Python
- 전처리
- backpropagation
- Convolutional Neural Network
- 비샤몬당
- 역전파
- SQL
- A Neural Algorithm of Artistic Style
- Today
- Total
통계, IT, AI
딥러닝: 화풍을 모방하기 (8) - 연습: 역전파법 본문
1. 회귀문제
- 본 포스팅에 있는 결과는 다음 첨부파일(code.7z)을 통하여 재현이 가능하다. code.7z
code.7z
- 역전파법을 회귀문제에 적용해보자. 실습을 위해 정의역이 \((-7,7)\)인 구간에서, \(\sin\)함수에 정규분포를 따르는 오차를 주어 적합해보자. 은닉층이 없는 경우와 있는 경우도 비교해본다. \(\epsilon\)과 같은 하이퍼 파라미터에 대한 설정은 첨부된 압축파일의 main_sin.py에 있다.

- 그림 1은 은닉층을 추가하지 않고 적합한 결과이다. 붉은 선은 \(\sin\)함수, 파란 점은 에러를 추가한 자료 그리고 주황 선이 적합한 결과이다. 출력층의 활성화함수가 항등함수이기 때문에 단순선형회귀의 결과와 같다.

- 그림 2는 같은 자료에 1개의 은닉층을 추가한 결과이다. 은닉층의 노드의 수는 3개이며 활성화함수로 모두 \(sigmoid\)함수를 사용하였다. \((-3,3)\) 구간에서는 그럴듯하게 적합이 됬다. 다른 구간의 적합은 만족스럽지 않은데, 하이퍼 파라미터를 조정하는 등의 작업을 거치면 개선의 여지가 있어 보인다.
2. 분류문제
- 분류문제를 실습하기 위하여 MNIST data set(이하 MNIST)를 사용한다. MNIST는 사람의 손글씨를 모아둔 자료로 60,000개의 훈련용 자료와 10,000개의 테스트용 자료로 구성되어 있다. 각 픽셀은 0부터 255의 값을 가지며 숫자가 클 수록 진한 부분이다. 그림 3은 MNIST의 예시이다.1

- 주의할 점은, 훈련을 시작하기 전에, 데이터의 각 값이 255에 의하여 나누어짐을 당하게 하여야 한다는 것이다. 이 나누어짐을 통하여 데이터의 값이 \([0,1]\)의 범위에 포함된다. 이 나누어짐은 너무나 중요하여 아무리 강조해도 지나침이 없는데, 이 포스팅을 올리는 사람이 그것을 하지 않아 3주 가까이 애꿎은 코드만 탓하며 시간을 보냈기 때문이다. 데이터를 그대로 사용할 경우, \(u^{(l)}\)이 지나치게 커져 안정적으로 계산가능한 활성화함수의 정의역을 벗어나버린다. 데이터의 전처리가 얼마나 중요한지 알게 된 경험이었다.
- 회귀문제와 마찬가지로 은닉층이 있는 경우와 없는 경우를 각각 비교해보자. 하이퍼 파라미터에 대한 자세한 설정은 첨부파일의 main_mnist.py에 있다. 결과를 재현해보고자 한다면 첨부파일의 mnist 폴더의 mnist_loader.py를 먼저 실행시켜야 한다.2

- 그림 4는 테스트 데이터에 대하여 은닉층이 없을 때와 1개 있을 경우 epoch에 따라 변하는 정확도를 표시한 것이다. 붉은 선이 은닉층이 존재하는 신경망의 결과, 파란 선이 없는 신경망의 결과이다. 은닉층이 없는 경우, 두개 이상의 class가 있는 logistic regression과 같다. 은닉층이 없는 경우 epoch을 거듭해도 학습을 하는 모습을 보여주지 못하고 있다.
3. Gradient Vanishing
- 회귀와 분류문제에서 공통적으로 은닉층을 추가하였을때 더 좋은 결과가 나옴을 확인할 수 있다. 그렇다면 은닉층을 많이 추가한다면 그만큼 좋은 결과가 나올까? 이를 확인하기 위하여 분류문제에서 15개의 은닉층을 설정하여 훈련을 진행하였다. 하이퍼 파라미터에 대한 정보는 main_gradient_vanishing.py에 있다.

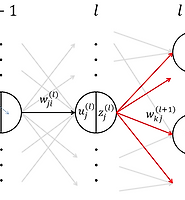
- 지속적으로 10%의 정확도를 보이는데, 10%의 정확도라는 것은 임의로 결정하는 것 즉, 찍는 것과 다름이없다. 왜 이런 결과를 보일까? \(\Delta^{(l)}= \partial E(\boldsymbol{w})/\partial u^{(l)}\)의 값이 입력층에 가깝게 갈수록 작은 값을 갖기 때문이다. 이를 확인하기 위해서는 NeuralNetwork.py의 88번째 출의 주석을 해제하면 된다.
- \(\Delta^{(l)}\)가 입력층으로 갈수록 작은 값을 갖는 이유는 역전파법이 선형계산이며 활성화함수로 \(sigmoid\)함수를 사용했기 때문이다. 즉, \(sigmoid\)의 형태상 입력값이 너무 크거나 작으면 기울이가 0에 가깝게 되고 이것이 선형관계를 따라 입력층으로 전파된다.
- 이것을 해결하기 위하여 3장에서 소개한 방법이 어느정도 도움이 되긴 하지만 본질적인 해결책은 아니며 이 기울기 소실을 해결하기 위한 방법으로 소개된 것이 앞으로 소개할 사전학습이다.
'머신러닝' 카테고리의 다른 글
| 딥러닝: 화풍을 모방하기 (10) - 연습: 자기부호화기(Autoencoder) (0) | 2017.04.30 |
|---|---|
| 딥러닝: 화풍을 모방하기 (9) - 책 요약: 5. 자기부호화기 (0) | 2017.04.17 |
| 딥러닝: 화풍을 모방하기 (7) - 책 요약: 4. 역전파법 (0) | 2017.02.16 |
| 딥러닝: 화풍을 모방하기 (6) - 연습: 다클래스 분류 문제 (1) | 2017.02.02 |
| 딥러닝: 화풍을 모방하기 (5) - 연습: 이진 분류 문제 (0) | 2017.02.01 |