| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 소인수분해
- Gram matrix
- CNN
- c#
- SQL
- 히토요시
- bayesian
- 딥러닝
- 역전파법
- Autoencoder
- 합성곱 신경망
- Python
- 베이지안
- 신경망
- 역전파
- project euler
- 전처리
- 비샤몬당
- neural network
- A Neural Algorithm of Artistic Style
- 오일러 프로젝트
- 수달
- deep learning
- 소수
- backpropagation
- 오토인코더
- Convolutional Neural Network
- mnist
- 냥코 센세
- 자전거 여행
- Today
- Total
통계, IT, AI
딥러닝: 화풍을 모방하기 (2) - 책 요약: 2. 앞먹임 신경망 본문
2. 앞먹임 신경망: Feedforward Neural Network
2.1 유닛의 출력
- 앞먹임 신경망은 층(layer) 모양으로 늘어선 유닛이 인접한 층과 결합한 구조이다.
- 정보가 입력 측에서 출력 측으로만 흐르기 때문에 Feedforward라는 이름이 붙여졌다.
- Multi-layer perceptron이라고도 부르지만 최초 제안된 perceptron은 입출력 함수가 step 함수로만 제한되었기 때문에 약간 다르다.
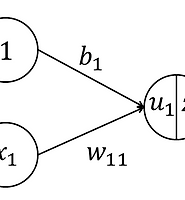
- 유닛 한 개의 입출력의 예시는 아래와 같다.

- 이 유닛이 받는 총 입력은 \(u_1=b_1+w_{11}x_1+w_{12}x_2+w_{13}x_3+w_{14}x_4\)이다.
- \(b_1\)은 bias라고 부르며 1에 곱해지는 가중치이다.
- \(w_{ji}\)1는 입력에 대한 가중치이며 \(b_{1}\)은 회귀분석에서 y 절편과 같은 역할이다.
- \(z_1\)는 \(u_1\)에 활성화 함수를 적용한 값으로 \(z_1=f(u_1)\)이다.
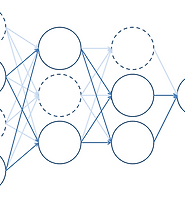
- 여러 출력을 갖는 신경망의 예시는 그림 2-2와 같다.

- 첫번째 층의 유닛의 수를 \(i=1,\cdots,I\), 두번째 층의 유닛의 수를 \(j=1,\cdots,J\)라고 하자.
- 두번째 층의 입력과 출력을 다음과 같이 쓸 수 있다.
$$u_j=\sum_{i=1}^{I}w_{ji}x_i+b_j, \quad z_j=f(u_j)$$
- 벡터와 행렬 표기법을 사용하면 다음과 같다.
$$\boldsymbol{u=Xw+b, \quad z=f(u)}$$
$$\boldsymbol{X}=\begin{bmatrix} x_1 \\ \cdots \\ x_I \end{bmatrix}^T, \boldsymbol{w}=\begin{bmatrix}w_{11} & \cdots & w_{J1}\\ \vdots & \ddots & \vdots \\ w_{1I} & \cdots & w_{JI} \end{bmatrix}, \boldsymbol{b}=\begin{bmatrix} b_1\\ \vdots \\ b_J \end{bmatrix}^T, \boldsymbol{u}=\begin{bmatrix} u_1\\ \vdots \\ u_J \end{bmatrix}^T, \boldsymbol{z}=\begin{bmatrix} f(u_1)\\ \vdots \\ f(u_J) \end{bmatrix}^T=\begin{bmatrix} z_1\\ \vdots \\ z_J \end{bmatrix}^T$$
2.2 활성화 함수
- 유닛의 활성화 함수로는 통상적으로 단조증가하는 비선형함수가 사용된다.
- 가장 많이 사용되는 함수는 로지스틱 함수(logistic function)로 다음과 같은 형태를 갖는다.
$$f(u)=\frac{1}{1+e^{-u}}$$
- 로지스틱과 유사한 형태를 보이는 함수로 쌍곡선 접점함수도 있다.
$$ f(u)=tanh(u)=\frac{e^u-e^{-u}}{e^u+e^{-u}}$$
- 두 함수 모두 출력의 상하한선이 존재하며 그 사이의 값에 대해서 서서히 변화하는 특징을 갖는다.
- 최근에는 단순하고 계산량도 적어 학습이 빠른 램프함수를 더 많이 사용하며 그 형태는 다음과 같다.
$$ f(u)=max(0,u) $$
- 그림 2-3은 자주 사용되는 활성화 함수이며 이를 그리기 위한 코드를 첨부한다.  figure_2_3.R
figure_2_3.R

- 이외에도 항등함수, 소프트맥스, 맥스함수 등이 사용된다.
- 최근에는 퍼포먼스의 문제로 Prameric Rectifiers도 사용한다고 하였다. 이 함수는 다음과 같은 정의를 갖는다. 단, \(a\)는 0보다 작은 상수이다.
$$ \begin{eqnarray}f(x) = \begin{cases} x & x \geqq 0 \\ ax & x<0 \end{cases}\end{eqnarray} $$
- 여기에 덧붙여 BatchNormalization이라는 방법도 사용된다.
2.3 다층 신경망
- 이상의 내용을 임의의 \(L\)개의 층수를 갖는 신경망으로 일반화 할 수 있다.
- 즉, 층 \(l+1\)의 출력 \(\boldsymbol{z}^{(l+1)}\)은 바로 이전 층\(l\)의 출력 \(\boldsymbol{z}^{(l)}\)로부터 다음과 같이 계산할 수 있다. 단, 윗첨자는 해당 층을 나타낸다.
$$\boldsymbol{u}^{(l+1)}=\boldsymbol{z}^{(l)}\boldsymbol{w}^{(l+1)}+ \boldsymbol{b}^{(l+1)}, \quad \boldsymbol{z}^{(l+1)}=\boldsymbol{f}(\boldsymbol{u^{(l+1)}})$$
-\(\boldsymbol{z}^{(1)}=X\)이며 최종 층의 출력 \(\boldsymbol{y}\)는 \(\boldsymbol{z}^{(L)}\)과 같다. 활성화 함수 \(\boldsymbol{f}\)는 각 층 그리고 각 유닛마다 서로 다른 것을 사용할 수도 있다.
- 앞먹임 신경망은 주어진 \(X\)에 대하여 입력층에서 출력층 방향으로 앞선 계산을 반복하는 함수이다.
- 이 함수를 결정하는 것은 \(\boldsymbol{w}^{(l)}\)과 \(\boldsymbol{b}^{(l)}\)이며 이들을 파라미터라고 부른다.
- 파라미터들을 간결하게 \(\boldsymbol{w}\)라고 표현하며 함수는 \(\boldsymbol{y(x;w)}\)라고 표현한다.
2.4 출력층의 설계와 오차함수
2.4.1 학습의 얼개
- 하나의 입력 \(x_i\)에 대하여 바람직한 출력을 \(\boldsymbol{d}_i\)라고 하자. \(\boldsymbol{d}_i\)는 스칼라일 수도 있고 벡터일 수도 있다.
- 학습이란 모든 입출력 쌍에 대하여 \(\boldsymbol{y(x_i;w)}\)가 최대한 \(\boldsymbol{d}_i\)에 가까워지도록 \(\boldsymbol{w}\)를 조절하는 과정이다.
- 이때 \(\boldsymbol{y(x_i;w)}\)가 \(\boldsymbol{d}_i\)에 가까운 정도를 측정해야 하는데 이 척도를 오차함수(error function)라고 부른다.
2.4.2 회귀
- 출력이 연속적인 값을 가지는 경우 파라미터를 찾는 문제를 회귀라고 한다.
- 출력과 같은 치역을 갖는 함수를 출력층의 활성화 함수로 고르는 것이 좋다.
- 회귀 문제의 경우 오차 함수 \(E(\boldsymbol{w})\)는 아래와 같다.
$$E(\boldsymbol{w})=\frac{1}{2}\sum_{i=1}^{N}\left\| \boldsymbol{y(x_i;w)}-\boldsymbol{d}_i \right\|^2$$
2.4.3 이진 분류
- \(x\)에 따라 출력이 두 종류(\(d\in[0,1]\))인 문제를 이진 분류라고 한다.
- \(x\)가 정해져 있을 때 \(d=1\)이 되는 사후확률 \(p(d=1|x)\)을 추정한다.
- 확률의 범위는 \((0,1)\)이므로 \(\boldsymbol{z}^{(L)}\)은 로지스틱 함수를 사용하여 구한다.
- \(d\)가 binary distribution을 따르므로 \(\boldsymbol{w}\)의 데이터에 대한 우도 함수(likelihood function)을 다음과 같다.
$$L(\boldsymbol{w})=\prod_{i=1}^{N}p(d_i|x_i;\boldsymbol{w})=\prod_{i=1}^{N}\left\{ y(x_i;\boldsymbol{w}) \right\}^{d_i}\left\{ 1-y(x_i;\boldsymbol{w}) \right\}^{1-d_i}$$
- 이 우도에 로그를 취하고 최소화를 위하여 부호를 바꾼 후 오차함수로 한다.
$$E(\boldsymbol{w})=-\sum_{i=1}^{N}\left[ d_ilog\left\{ y(x_i;\boldsymbol{w}) \right\}+(1-d_i)log\left\{ 1-y(x_i;\boldsymbol{w}) \right\} \right]$$
2.4.4 다클래스 분류
- \(x\)에 따라 출력이 두 종류 이상인 문제를 이진 분류라고 한다.
- \(x\)가 정해져 있을 때 \(d=k\)이 되는 사후확률 \(p(d=k|x)\)을 추정한다.
- \(\boldsymbol{z}^{(L)}\)은 소프트맥스 함수를 사용하여 구한다.
- 즉, 이 출력층의 \(k\)번째 유닛의 출력은 다음과 같다.
$$y_k=\boldsymbol{z}_k^{(L)}=\frac{exp\left(u_k^{(L)}\right)}{\sum_{j=1}^{K}exp\left(u_j^{(L)}\right)}$$
- 정의에 의하여 출력의 합은 항상 1이 된다.
- \(d\)가 categorical distribution을 따르므로 이진 분류와 유사하게 오차함수를 정의할 수 있으며 이 함수를 교차 엔트로피(corss entropy)라고 부른다.
$$E(\boldsymbol{w})=-\sum_{i=1}^{N}\sum_{k=1}^{K}d_{ik}log\left\{y_k(x_i;\boldsymbol{w})\right\}$$
- 단, \(d_{ik}\)는 i번째 sample이 k class를 가질때 0 그렇지 않으면 1의 값을 갖는다.
- 전층의 i번째 출력이 다음 층의 j번째 입력으로 전달될 때의 가중치 [본문으로]
'머신러닝' 카테고리의 다른 글
| 딥러닝: 화풍을 모방하기 (5) - 연습: 이진 분류 문제 (0) | 2017.02.01 |
|---|---|
| 딥러닝: 화풍을 모방하기 (4) - 연습: 회귀 문제 (0) | 2017.01.30 |
| 딥러닝: 화풍을 모방하기 (3) - 책 요약: 3. 확률적 경사 하강법 (1) | 2017.01.30 |
| 딥러닝: 화풍을 모방하기 (1) - 책 요약: 1. 시작하며 (0) | 2017.01.27 |
| 딥러닝: 화풍을 모방하기 - 시작하며 (0) | 2017.01.27 |